

友人からの「そもそも機械学習ってなんなの?」「機械(コンピューター)がどうやって学習しているの?」という問いかけをきっかけに機械学習がどのようにデータを学習しているかについてコラムにしてみました。過去のコラムで機械学習の教師あり学習と呼ばれる「回帰木」「分類木」の仕組みを紹介しました。(もしよろしかったら過去のコラムも読んでみてくださいね)
教師あり学習は一つのデータ項目「お料理の得点」や「行く、行かない」を教師データとして、他のデータ項目で教師データを学習するといった手法です。
今回は機械学習の中で教師なし学習のクラスタリングと呼ばれる手法を紹介したいと思います。文字どうり教師となるデータを指定せずにデータを学習する手法です。
クラスタリングにはいくつかの手法がありますが、今回はクラスタの構造が分かりやすい階層型クラスタを紹介します。
データ分析を生業にしているものとして恥ずかしいのですが、友人からのある素朴な質問にすぐに答えられなかったことがありました。それは「そもそも機械学習ってなんなの?」「機械(コンピューター)がどうやって学習してるの?」という問いかけでした。
私が考える「機械(コンピューター)がどうやって学習してるの?」への回答は「機械(コンピューター)がデータのパターンを記憶する」ために「データのパターンを自動で数式やルールにして記憶する、または自動で分類する」かなと思っています。
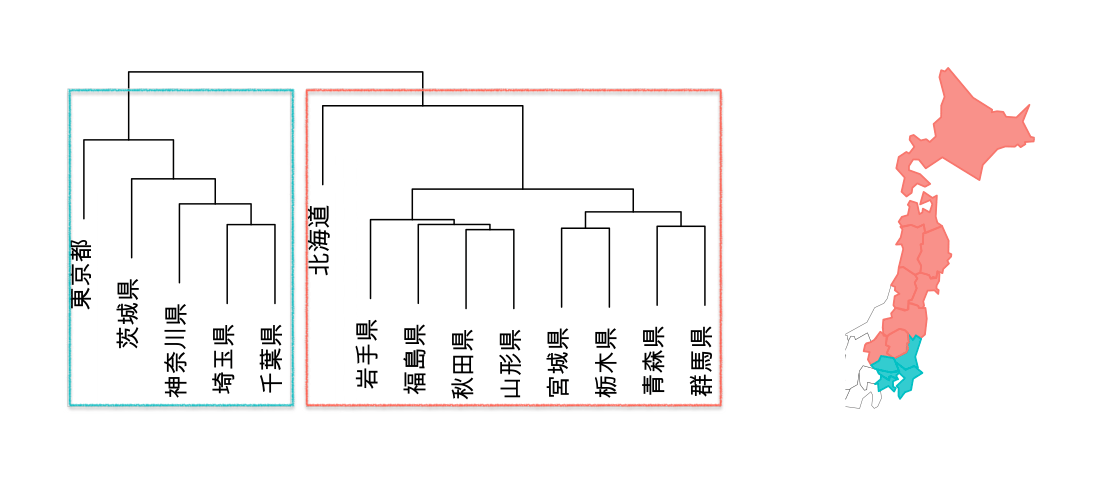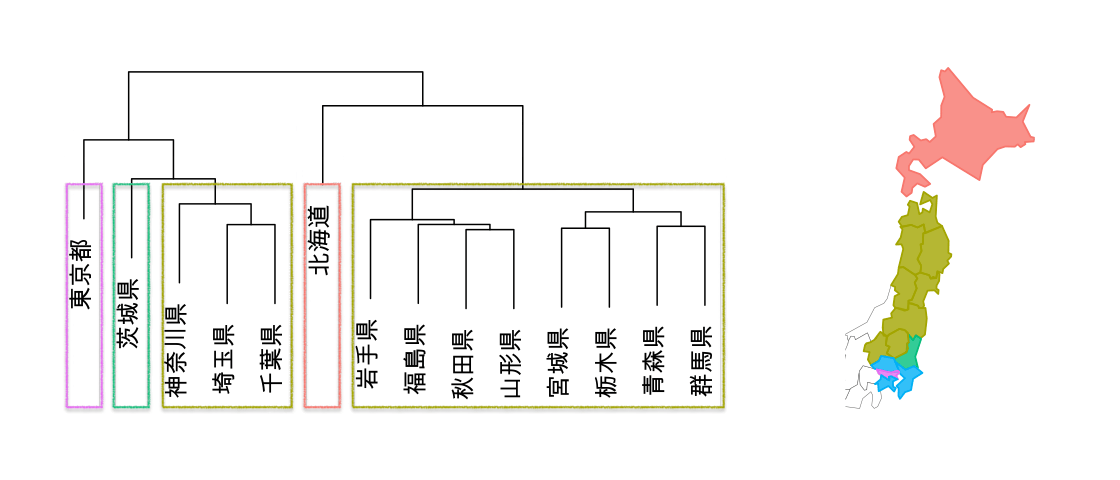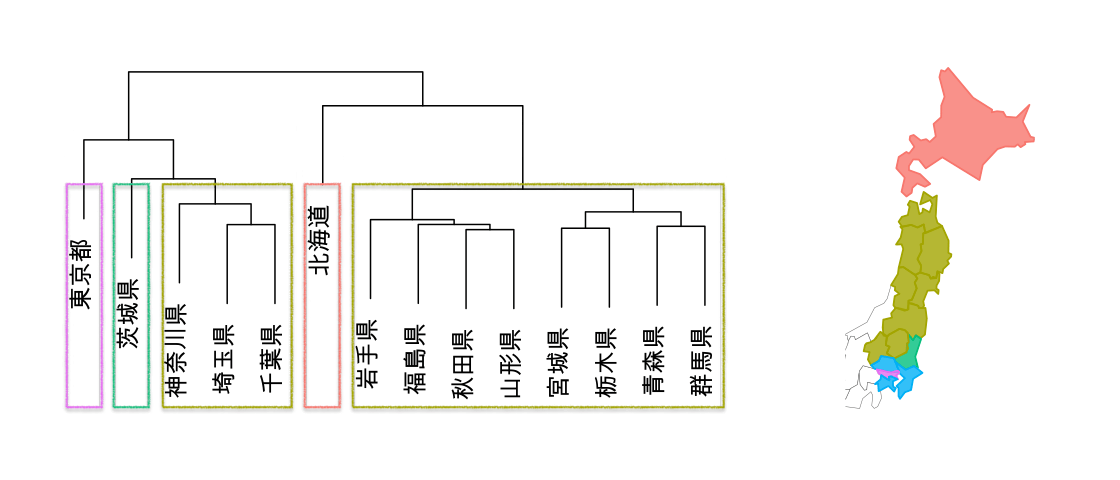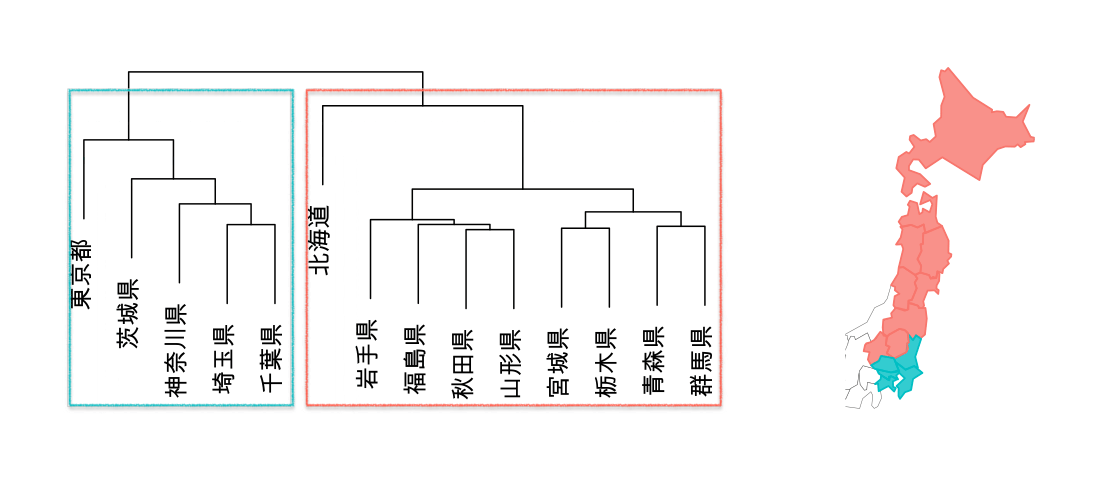
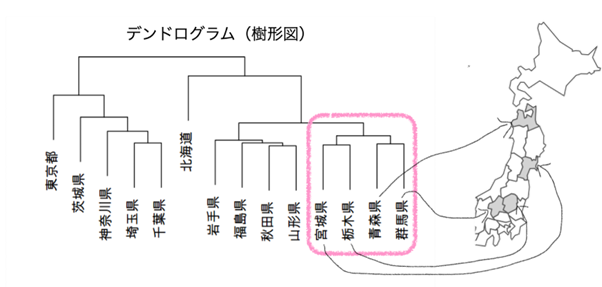
唐突ですが、以下のグラフを見ていただきたいと思います。 このグラフはデンドログラムと呼ばれていて、日本語では樹形図、樹系図、樹状図など幅広い呼び方があるようです。このデンドログラムは階層型クラスタという手法でデータをグループ分けした構造を表しています。
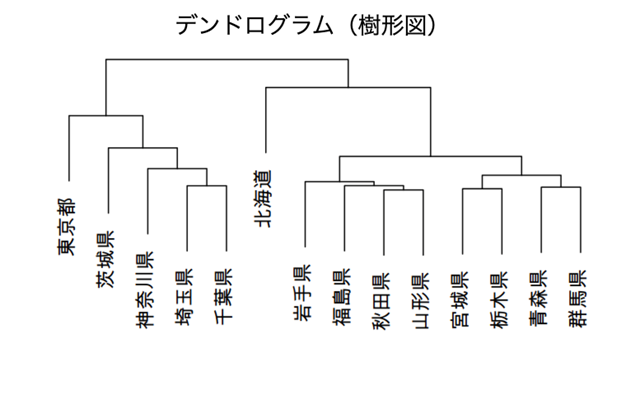
使用したデータ項目は都道府県別の「人口」、「面積」と「森林面積割合」の3種類です。都道府県47のうち北海道、東北地方、関東地方の14の都道府県を使用しました。
データ出典:総務省「統計でみる都道府県のすがた」の2024年版
https://www.stat.go.jp/data/k-sugata/index.html
階層型クラスタは似ている順にグループ(以降クラスタと呼びますね)にしていって、階層に積み上げていく手法です。デンドログラムを使うと上から順に枝分かれしてクラスタ分けされていく様子が分かります。アニメーションにしてみましょう。
階層型クラスタはグループ分けの個数と、各グループのメンバーがどう変わるかといったことが直感的にわかります。
それでは、階層型クラスタがデータを学習する手順を見ていきましょう。
階層型クラスタはデータごとの類似度を計算して似ている順にクラスタにしていきます。
今回はデータの類似度の算出に「ユークリッド距離」、似ている順にクラスタにする方法に「完全連結法」を使用します。
まずはデータを学習するため準備としてデータ値の標準化*を行います。
使用したデータ項目の単位は人口であったり、面積であったり割合(パーセンテージ)とばらばらです。これらの違いを同じ尺度にするために、データ項目ごとの平均と標準偏差を使って尺度を合わせます。下のグラフは左側が元データをそのまま使ったグラフで、右側がそれぞれのデータ項目の値を*標準化した後のグラフです。
*標準化
(「データ項目のそれぞれの値」ー「データ項目の平均値」)/「データ項目の標準偏差」
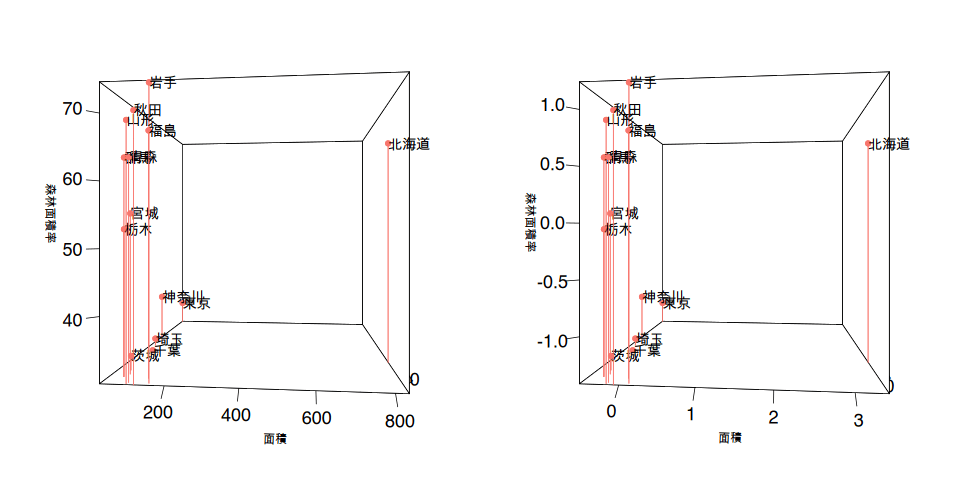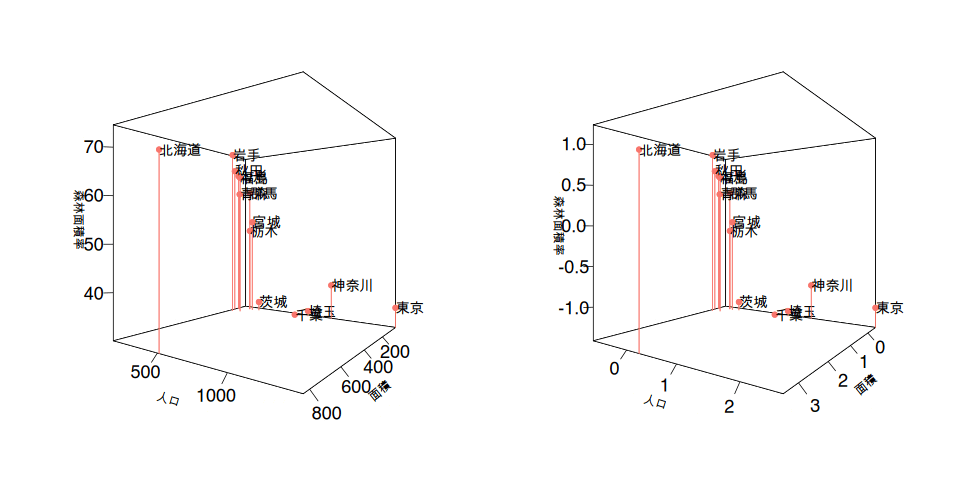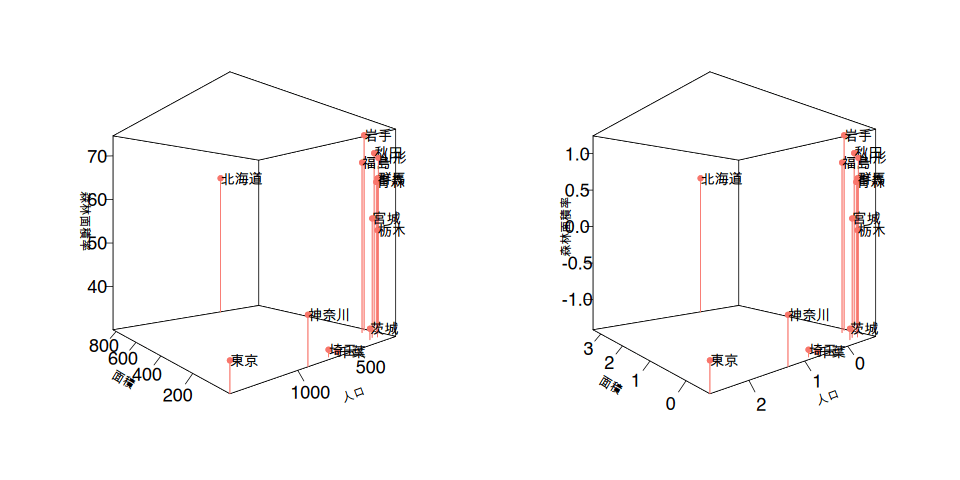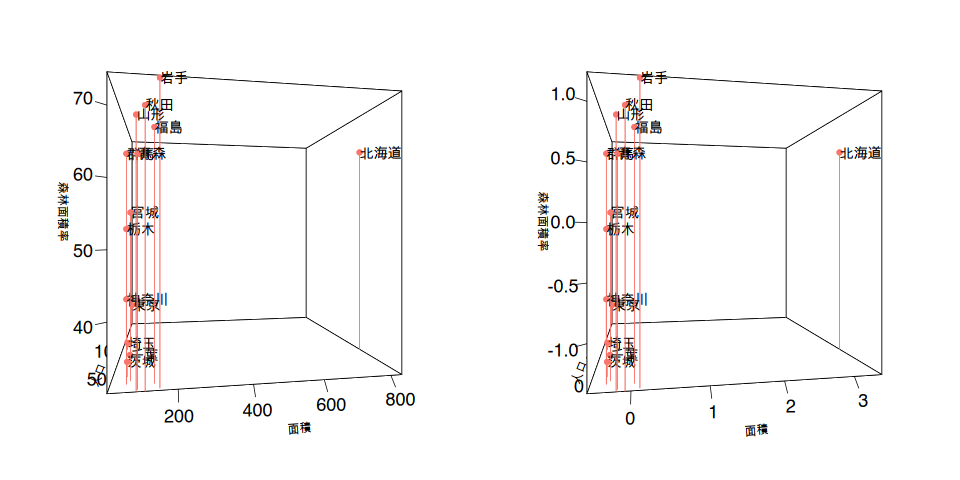
3次元のプロットの位置関係は変わらないのですが、右側のグラフは平均値を0とした値に変わっているのが分かると思います。数値の標準化によって異なる尺度の値を平均値を使った同じ尺度で比べられるようになります。
階層型クラスタがデータを学習するための準備(データ値の標準化)が終わりました。
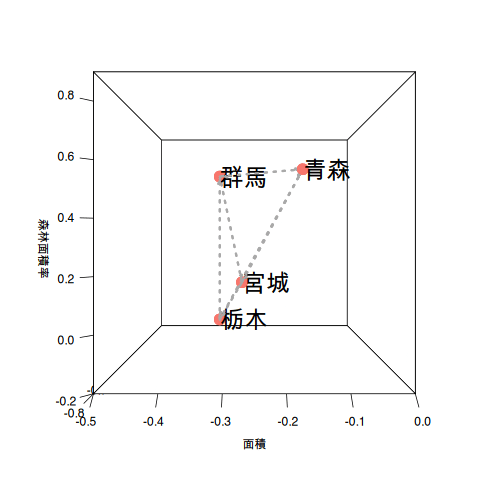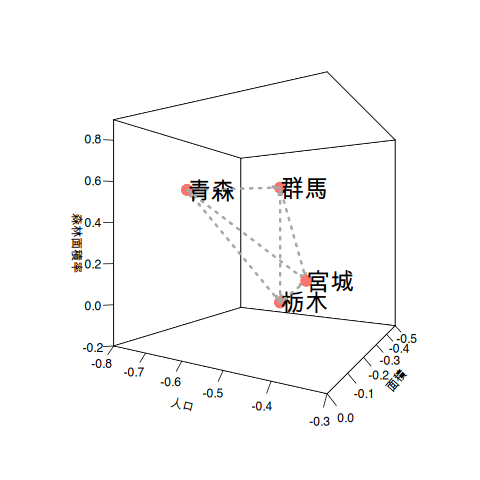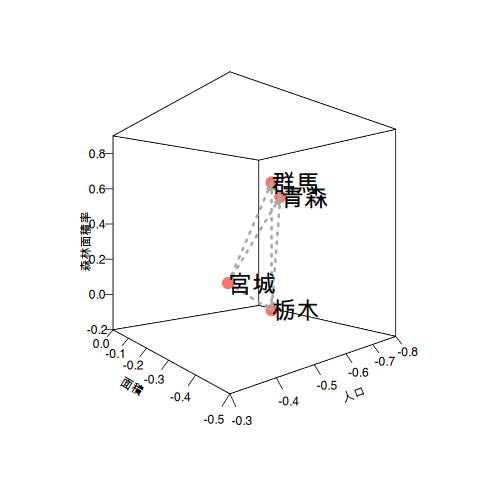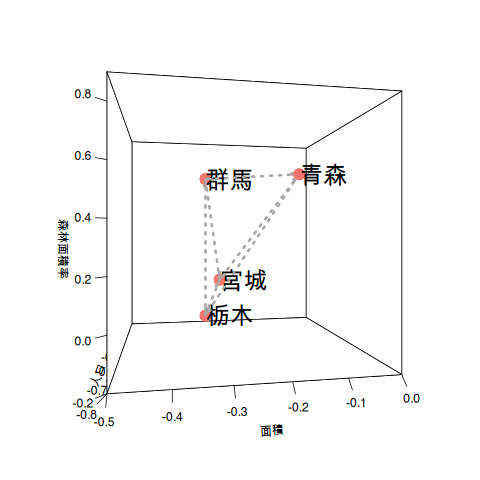
都道府県が14もあると分かりづらいのでデンドログラムの右端の4県(宮城県、栃木県、青森県、群馬県)を取り出して説明させてください。
今回は県ごとの類似度の算出に「ユークリッド距離」を使います。
具体例として青森県と宮城県を例にしてユークリッド距離を計算してみましょう。
今回の3種類のデータ項目(人口、面積、森林面積率)の場合、ユークリッド距離は以下の式で算出されます。
ユークリッド距離 =√(人口*の差)2+(面積*の差)2+(森林面積率*の差)2
*標準化後の値
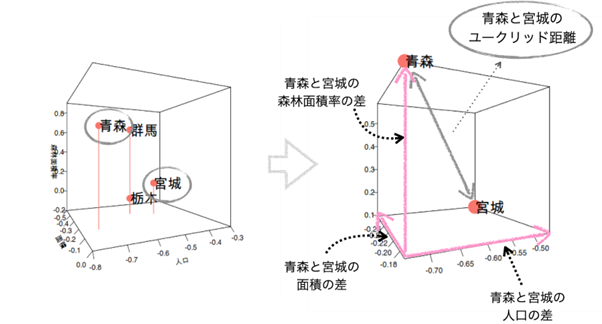
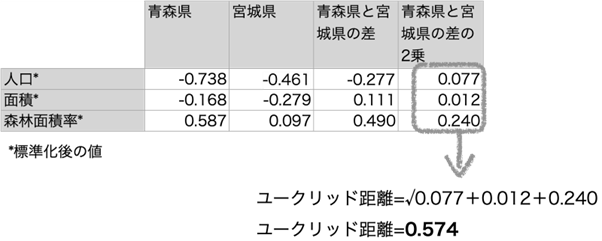
データ項目が3個の場合は立方体の対角線の距離の求め方と同じですね。
データ出典の総務省「統計でみる都道府県のすがた」には今回使用した人口、面積、森林面積率の他にも「第一次産業(農業、林業、漁業)従事者率」や「持ち家比率」などさまざまなデータ項目が集計されています。
分析対象のデータ項目が3個を超えると3次元グラフでは可視化できなくなってしまうのですが、データ項目ごとの差の2乗の合計の平方根が青森県と岩手県のユークリッド距離になります。
ユークリッド距離 =√(人口*の差)2+(面積*の差)2+(森林面積率*の差)2+(…*の差)2+…
*標準化後の値

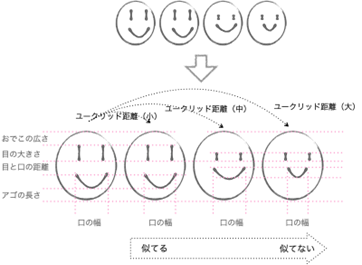
3個を超えるデータ項目の場合のユークリッド距離について、顔のイラストでイメージしてみましょう。
下のイラストは顔に関するサイズ(おでこの広さ、目の大きさ、目と口の距離、アゴの長さ、口の幅)といったデータ項目5個を少しづつ変えたものです。
データ項目ごと(おでこの広さや目の高さなど)の値の差が小さければ似ていて(ユークリッド距離が小さく)差が大きければ似ていない(ユークリッド距離が大きい)といったイメージです。
ユークリッド距離の算出方法が分かりましたので、次にクラスタ分類の仕組みを見ていきましょう。
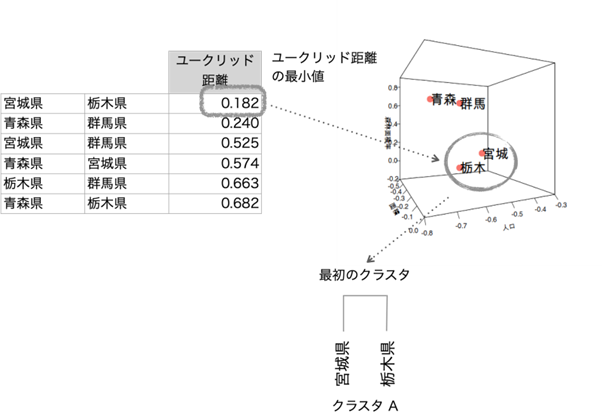
階層クラスタの分類にはいくつか方法があってデータの特性で使い分けるのですが、今回は「完全連結法(最長距離法)」を紹介します。 まず4つの県のユークリッド距離を総当たりで算出します。6通りの組合せがあります。
最初のステップは4つの県のユークリッド距離の組合せから最もユークリッド距離の短いペア(最も似ている県のペア)を最初のクラスタ(下図のクラスタA)にします。
次にクラスタAとクラスタAに含まれない青森県と群馬県のユークリッド距離を決めます。
この時クラスタAのメンバーとの「最も長い距離」を使用するのが完全連結法(最長距離法)です。
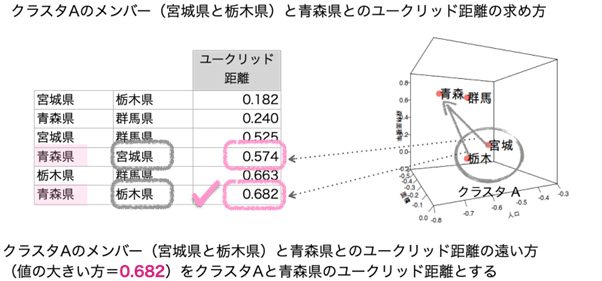
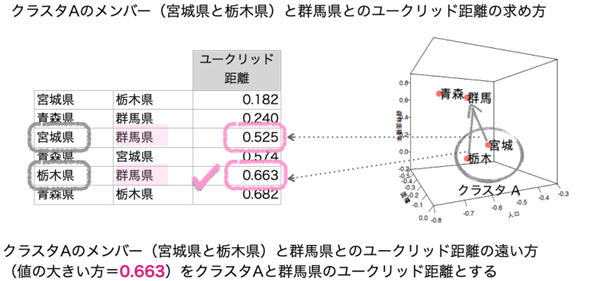
クラスタAと青森県と群馬県のユークリッド距離がそれぞれ求まりました。
この値を使って、最もユークリッド距離の短いペア(最も似ているペア)を次のクラスタにします。
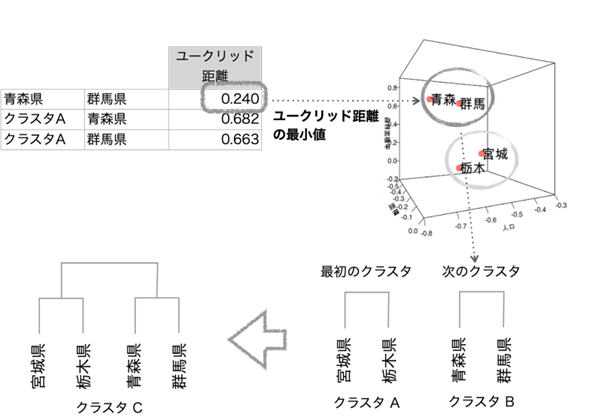
データが2つのクラスタに集約されましたので、最後に2つのクラスタを結合して終了します。階層型クラスタはこの仕組みで全てのデータのユークリッド距離を総当たりで比べて順々にクラスタのメンバーを増やして積み上げていくんですよ。
さて、階層型クラスタでデータをグループ分けする仕組みが分かりました。
階層型クラスタは教師なし学習と呼ばれるもので、教師なし学習で分類された場合、各クラスタの特徴を後付けで解釈しないとクラスタA、B、C…ではよく分かりませんよね。
一方、以前のコラムで紹介した教師あり学習の分類木は、例えば教師データ「紅葉狩りに行く、行かない」に対してデータを分割していくので、このグループは紅葉狩りに行くというようにグループの特徴が明確です。
それでは、教師なし学習の別の手法を利用してクラスタに名前をつけてみましょう。
せっかくなので、47の全ての都道府県を階層型クラスタで分類して各クラスタに名前をつけてみますね。
まずは47都道府県を階層型クラスタで9個(AからI)に分類しました。

各クラスタに名前をつけるために、主成分分析*という手法で3つのデータ項目(人口、面積、森林面積率)を2つのデータ項目に圧縮して各クラスタのデータ特徴を可視化してみましょう。
*主成分分析:複数のデータ項目の値の広がり(ばらつき)が最大となる方向を見つけ出し、その方向を新たな軸として主成分というデータに合成してデータの次元を削減する手法です。主成分分析の仕組みについてはまたの機会に紹介したいと思います。
下のグラフは主成分分析の結果、新たに合成された第1主成分を横軸、第2主成分を縦軸にプロットしたものです。
クラスタAからIまで色分けされたプロット点がそれぞれ都道府県を表しています。 グラフ内に人口、面積、森林面積率としてグレーのラインで示されている矢印がそれぞれのデータ項目ごとの軸になります、右にいくほど人口が多い、左上にいくほど面積が広い、左にいくほど森林面積率が高いといった大まかな解釈ができます。
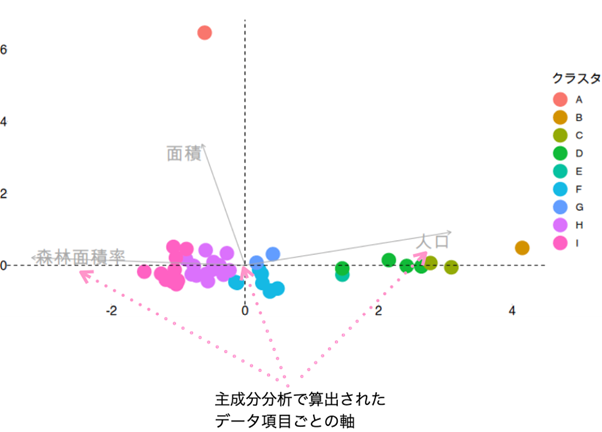
それでは、クラスタに名前を付けてみたいと思います。
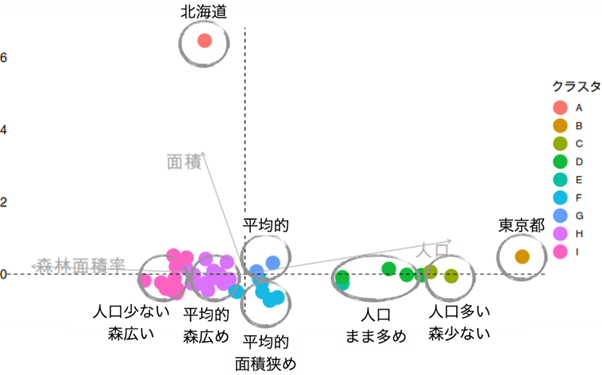
「クラスタA」と「クラスタB」はクラスタに1つの都道府県しかないので、そのまま「北海道」「東京都」としました。
「クラスタC」は「人口多い森少ない」としますね、含まれるのは「神奈川県」と「大阪府」です。
「クラスタD」と「クラスタE」は「人口まま多め」としましょう、含まれるのは「埼玉県」「千葉県」「愛知県」「福岡県」「茨城県」です。
このような調子で名前をつけると、「人口少ない森広いクラスタ」、「平均的面積狭めクラスタ」などA,B,C…と比べるとクラスタの特徴が直感的に分かるようになります。
今回は都道府県の3つのデータ項目(人口、面積、森林面積率)を使って、似ている都道府県を機械学習で分類してみました。各都道府県のさまざまなデータ項目を追加しても同じ仕組みで分類できます。
冒頭の
「機械(コンピューター)がどうやって学習してるの?」への回答として
データを渡すだけ機械学習がルールにしたがってデータを学習して自動でデータを分類することができたと思います。
クラスタ分析は、アンケート回答結果からユーザを分類するなど、データを大まかに理解したいときなど活用できる場面は多くあります。
また複数データ項目の組合せでグルーピングしますので、項目ごとの集計では気づかない発見がよくあるんですよ。皆さんもぜひ活用いただければと思います。
ありがとうございました。
機械学習の基礎となる知識をできるだけ簡単に説明してみました。
使い方次第では便利なツールであるというイメージを少しは持てましたでしょうか?
もし機械学習を使ったら「こんなこともできちゃうのかな?」みたいなご質問があれば
遠慮なく、お問い合わせフォームにご連絡いただければと思います。
またこのような仕事に興味がある方も積極採用しておりますので、応募お待ちしております。
関連記事
